Data Organization
Suggested Data Organization
To aid in the curation of scientific papers we suggest the following data organization. However, Qresp does not require a specific organization and you may choose your own.
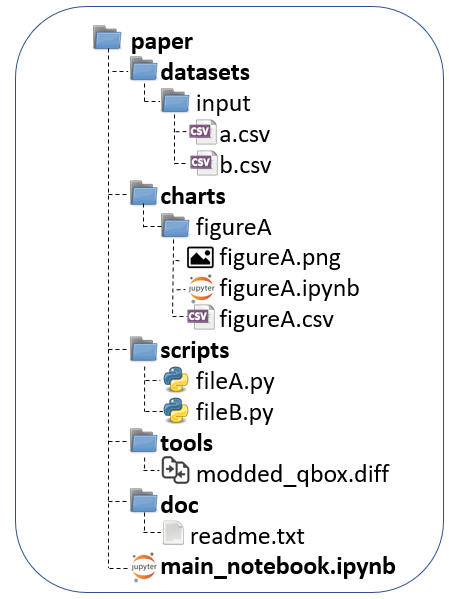
These folders should comprise all data and scripts you have used in your project.
- datasets: This folder contains raw data generated in the scientific paper i.e. datasets created by an instrument or by a versioned software.
- charts: This folder contains the images (e.g. figureA.png) of figures and tables and the notebooks (e.g. figureA.ipynb) used to create them. Data files (e.g. figureA.csv) contain exclusively the data displayed in the figures & tables.
- scripts: This folder contains source codes (e.g. fileA.py, fileB.py) not available publicly, used to manipulate datasets and generate the data files of charts, or other data discussed in the scientific paper.
- tools: This folder contains patches of publicly available or versioned software, customized by the user to generate some of the datasets.
- docs: This folder contains documentation that the user may want to provide in addition to that reported in notebooks and in the scientific paper, for example tutorials.
- toc.ipynb: This notebook file serves as a table of contents and may contain links to all datasets, charts, scripts, tools and doc.
Data Location and Access
The organized data should be located on a server that is accessible to the public by running a http service, e.g. Apache. This is required to use the exploration feature of Qresp.
-
Globus to make the data shareable and downloadable via grid FTP (recommended for large datasets).
-
Git to version control the data.
Important
Make sure the file permissions are set to read for anyone, otherwise the data won't be accessible over the internet. An easy way to do this (on linux) for all the files/folders is to run chmod -R a+r * inside your data folder.